






بقلم وسيم صافي
باحث في المعهد العالي
عملت مواقع التواصل الاجتماعي (Social Media sites) على تحقيق نقلة نوعية في مجال تواصل الأفراد بعضهم ببعض وفي مجال نقل معلوماتهم وأخبارهم بسرعة وبأسلوبٍ جديدٍ وفعالٍ. ذلك بأنّ الانتشار الكبير والمتزايد لأعداد المنتسبين إلى شبكات التواصل الاجتماعي الخاصة بهذه المواقع أجبر الكثير من الشركات على إعادة صياغة استراتيجياتها التسويقية، كما أجبر العديد من مطوري ومحللي النظم على إدراج مكونات خاصة للتعامل مع هذه المواقع. وأدى هذا الانتشار أيضًا إلى إيجاد توجهات جديدة في الأبحاث المتعلقة ببعض النظم بغية الاستفادة قدر الإمكان من مكنونات المعلومات والروابط والعلاقات الموجودة في هذه الشبكات، ومنها الأبحاث الخاصة بنظم استرجاع المعلومات (Information Retrieval Systems).
تكمن أهمية نظم استرجاع المعلومات في قدرتها على تحليل جزء كبير من الكم الهائل من المعلومات الموجودة على شبكة الإنترنت، وفي قدرتها على تلبية حاجة الشخص عن طريق إعطائه المعلومة التي يبحث عنها بدقة وسرعة. تتمثل هذه النظم في عدة أساليب؛ منها: محركات البحث (Search Engines) التقليدية المعتمدة على الطرق الإحصائية كالأسلوب المتبع في عملاق محركات البحث غوغل، ومنها محركات البحث التي تتّبع منهجًا دلاليًّا (Semantic Approach) في البحث عن المعلومات. وقد تتمثل هذه النظم أيضًا في نظم الإجابة على الأسئلة (Question Answering Systems) وهو نمط متقدم جدًّا من نظم استرجاع المعلومات، حيث يجري دمج الخوارزميات التقليدية لمحركات البحث (محركات البحث غير المعتمدة على الطرق الدلالية) مع العديد من خوارزميات الاستدلال والطرق الدلالية، إضافة إلى كثير من تقنيات المعالجة الآلية للغات الطبيعية، وظهر مؤخرًا النمط الأحدث من نظم استرجاع المعلومات، وهو النوع المخصص لشبكات التواصل الاجتماعي.
نقدم في مقالنا هذه سردًا لأهم الدراسات في مجال نظم استرجاع المعلومات، وأهم الخوارزميات المستعملة فيها. ثم نتطرق إلى بعض النماذج والآليات التي تتبعها هذه النظم للتنقيب في المعلومات المضمنة في شبكات التواصل الاجتماعي. كما نوضح بعض النماذج التصميمية الخاصة بمثل هذه النظم. وأخيرًا نتطرق إلى أهم طرق تحليل وتقييم هذه النظم اعتمادًا على أدائها ضمن شبكات التواصل الاجتماعي.
بدايات نظم استرجاع المعلومات
تعود بدايات نظم استرجاع المعلومات إلى منتصف أربعينيات القرن العشرين، مع نهاية الحرب العالمية الثانية واستحواذ القوات الأمريكية على كمٍّ هائلٍ من الوثائق المكتوبة باللغة الألمانية التي تحتوي على معلومات عن الأسلحة الألمانية. وعندها بدأت تظهر العديد من التساؤلات عن ضرورة وجود طريقة ما لهيكلة المعلومات المضمنة في هذه الوثائق. ويعتبر المقال الذي نشره فانيفار بوش عام 1945 - والذي طرح فيه تساؤلًا عن الآليات الصحيحة لهيكلة ونمذجة المعلومات - من أهم المقالات التي صدرت في تلك المدة والتي رسمت لفترة طويلة معالم ما صار يعرف لاحقًا بنظم استرجاع المعلومات.
استمرت الأبحاث التي تهتم بهذا المجال حتى ظهر في بداية الثمانينيات من القرن العشرين مصطلح محركات البحث Search Engines، والتي اعتبرت حينها إحدى المرادفات لمصطلح نظم استرجاع المعلومات Information Retrieval Systems، ومنذ تلك الفترة تشهد نظم استرجاع المعلومات تقدمًا كبيرًا في طرق بحثها عن المعلومات.
آلية عمل نظم استرجاع المعلومات
تهدف نظم استرجاع المعلومات إلى الوصول السريع والدقيق للمعلومات التي يبحث عنها الشخص ضمن كمٍّ كبيرٍ من المعلومات. وتوجد هذه المعلومات في الوثائق بشكل صريح أو ضمني، وهنا تصبح عملية البحث أصعب وأشد تعقيدًا وبحاجة إلى مستويات متقدمة من تحليل المعلومات؛ ومنها المعالجة الآلية للغات الطبيعية.
تختلف الطرائق التي تتبعها نظم استرجاع المعلومات، إلا أنها جميعًا تتشارك في سيناريو عمل واحد. حيث يجري تحليل السؤال أو الاستعلام الذي يوجهه الشخص للنظام، فيقوم النظام باستخلاص مجموعة من الكلمات المفتاحية من هذا الاستعلام. ومن ثم يجري البحث ضمن المدونات Corpora عن مجموعة من الوثائق التي يمكن أن تحتوي هذه الكلمات المفتاحية. وبعدها يزوِّد النظامُ الشخصَ بقائمة من هذه الوثائق مرتبة وفق خوارزميات معينة، يوضح الشكل 1 الهيكلية العامة لأي نظام استرجاع معلومات.
الشكل 1: الهيكلية العامة لأي نظام استرجاع معلومات
تعتمد معظم نظم استرجاع المعلومات على الخوارزميات التقليدية في عملية البحث مثل خوارزميات البحث المعتمدة على المنطق البولياني (Boolean logic) وخوارزمية نموذج فضاء الأشعة (Vector Space Model) لمطابقة السؤال المطروح مع وثائق البحث.
تعتبر خوارزمية فضاء الأشعة (Vector Space) من أكثر الطرق استعمالًا في محركات البحث. وهي تعتمد على تمثيل كل وثيقة على شكل شعاع من الكلمات المفتاحية التي تميز هذه الوثيقة، وتمثيل الاستعلام أيضًا على شكل شعاع من الكلمات المفتاحية، ثم تجري مقارنة الشعاع الممثل للاستعلام مع الأشعة الممثلة للوثائق واختيار أكثرها قربًا من الاستعلام. يوجد عدة طرق لتمثيل شعاع الكلمات المفتاحية المميزة للوثيقة، منها طريقة التمثيل الثنائي Binary Representation، وطريقة التمثيل الموزَّن/المثقَّل Weighted Representation.
في طريقة التمثيل الثنائي يجري تمثيل تقاطع الوثائق documents ومجموعة المفردات terms بمصفوفة ثنائية، يمثل السطر الأول منها المفردات الموجودة في كل الوثائق، ويمثل العمود الأول كل الوثائق التي يجري البحث فيها. وبذلك تكون خلايا هذه المصفوفة عبارة عن أصفار ووحدان تدل على احتواء أو عدم احتواء كل وثيقة على مفردةٍ ما، الشكل 2 يوضح شكل هذه المصفوفة.
الشكل 2، مصفوفة التمثيل الثنائي في خوارزمية فضاء الأشعة
ونظرًا لكبر حجم الذاكرة المطلوبة لتمثيل هذه المصفوفة، يجري اتباع أسلوب أكثر فعالية في التمثيل وهو عدم تمثيل الخلايا التي تساوي قيمتها الصفر، كما هو موضح في الشكل 3.

الشكل 3: الشكل المختصر لمصفوفة التمثيل الثنائي في خوارزمية فضاء الأشعة
ولضمان سرعة البحث عن المفردات يجري عكس عملية التمثيل لتصبح المفردات هي المدخل الرئيسي للفهرس المنجز، كما هو موضح في الشكل 4. يُعْرَف هذا الفهرس باسم فهرس المفردات العكسي Inverted Term Index.
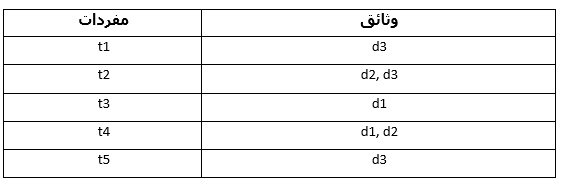
الشكل 4: فهرس المفردات العكسي
نظم استرجاع المعلومات على الوب
تختلف نظم استرجاع المعلومات على الوب عن نظم الاسترجاع التي تبحث ضمن مجموعة وثائق وملفات محددة سلفًا. وهنا يظهر مدى الصعوبة التي تواجهها نظم استرجاع المعلومات المخصصة لشبكات التواصل الاجتماعي، حيث تقسم الصعوبات التي تواجه هذه النظم على الوب إلى صنفين أساسيين؛ الأول يتعلق بالحجم الكبير للمعلومات الموجودة على الوب، والثاني يتعلق بالواجهات الخاصة بالشخص للتعبير عن المعلومات التي يرغب بالبحث عنها.
تتمثل الصعوبات التي تتعلق بالحجم الكبير للمعلومات الموجودة على الوب في التزايد المستمر للمعلومات على الوب وبشكل لحظي، وهذا يتطلب تجديد الفهارس باستمرار، إضافة إلى طريقة تمثيل المعلومات الموجودة ضمن الملفات. إذ يشكل التباين الكبير الموجود لأنواع الملفات وطريقة تمثيل كل منها إحدى الصعوبات التي تواجه هذا النوع من النظم.
أما الصعوبات التي تتعلق بالواجهات الخاصة بالشخص للتعبير عن المعلومات التي يرغب بالبحث عنها، فهي تنجم بالأساس من كون معظم الأشخاص السابقين لنظم استرجاع المعلومات غير الموجودة على الوب لديهم خبرة سابقة في التعامل مع هذه النظم وكيفية توليد الاستعلامات الخاصة بها. أما فيما الأشخاص الذين يستعملون هذه النظم على الوب فليست لديهم الخبرة الكافية للتعامل مع هذه النظم.
الانتشار المتزايد لمواقع التواصل الاجتماعي على الوب
يعتبر انتشار مواقع التواصل الاجتماعي والمدونات الخاصة من أهم ميزات الجيل الثاني من الوب Web2.0 والذي يوصف بأنه موجه بشكل أساسي إلى مشاركة الشخص User Participation Oriented. تتيح هذه المواقع للأشخاص نشر معلوماتهم الخاصة وإقامة الروابط التشاركية مع الآخرين مما يوفر سرعة في نقل أي معلومة يرغبون في نشرها. ونتيجةً لإقبال الأشخاص المستمر على هذه المواقع وشغفهم بالتواصل عن طريقها، تزايد اهتمام الشركات بالاستثمار فيها مما أدى إلى زيادة عددها وخدماتها. يوضح الشكل 5 قائمة بأهم مواقع التواصل الاجتماعي التي ظهرت في العقدين الأخيرين.
الشكل 5: قائمة أهم مواقع التواصل الاجتماعي
تتيح المواقع المذكورة الموضحة في القائمة السابقة العديد من الخدمات والميزات. ولكن أهم هذه الميزات هي إبقاء الأشخاص متصلين بعضهم ببعض عن طريق ميزة تحديثات الحالة Status Updates التي تتيح نقل أي تحديث في حالة الشخص إلى جميع الأشخاص الذين يرتبطون به. كما تجبر جميع المواقع السابقة إجراء اشتراك دخول Registration Inscription للاستفادة من خدماتها.
يعتبر موقعا فيسبوك facebook وتويتر Twitter من أكثر مواقع التواصل الاجتماعي شهرةً واستعمالًا وأكثرها تزايدًا في عدد المشتركين؛ فقد بلغ عدد المشتركين في الفيسبوك في حزيران 2006 قرابة 10 ملايين، وفي تشرين الثاني 2008 نحو 140 مليون، أي بزيادة 1400% خلال عام ونصف فقط. ووصل عددهم في 2009 إلى 350 مليون، وفي أواخر 2019 إلى أكثر من 1.6 مليار. يوضح الشكل 6 مثالًا على المنحني التزايدي لهذه الأعداد بين عامي 2006 و 2008.
الشكل 6: تزايد أعداد المشتركين في الفيسبوك بين عامي 2006 و 2008
نظم استرجاع المعلومات الموجهة إلى شبكات التواصل الاجتماعي
تتعامل نظم استرجاع المعلومات الموجهة إلى شبكات التواصل الاجتماعي بأسلوب مختلف عن تعاملها مع الوثائق الموجودة ضمن المدونات العادية. إذ تتميز هذه الشبكات باحتوائها على كمٍّ كبير من العلاقات Relations بين الصفحات الخاصة بأفرادها، كما تتميز بدرجة كبيرة من تشاركية المعلومات وتكرارها، وهذا ما يوجب على نظم استرجاع المعلومات اتباع استراتيجية خاصة عند البحث عن المعلومات ضمنها.
ثمة طرق مختلفة تتبعها نظم استرجاع المعلومات لتمثيل هذه الشبكات لتسهيل عملية البحث فيها. بعض هذه النظم تمثل معلومات الشبكة على شكل بيان Graph تمثل عقده مجموعة مستعملي الشبكة، وتمثل الروابط بين هذه العقد العلاقات بين مستعملي هذه الشبكة. يوضح الشكل 7 تمثيلًا افتراضيًّا لجزء بسيط من إحدى شبكات التواصل الاجتماعي، حيث يجري تمثيل درجة الارتباط بين الأشخاص بثخانة السهم الممثل للرابط بين العقد.
الشكل 7: استعمال مفاهيم البيانات لتمثيل شبكات التواصل الاجتماعي
تتبع بعض النظم الأخرى طرقًا أعقد في تمثيل شبكات التواصل الاجتماعي وذلك بتقسيم فضاء المعلومات إلى حيزين؛ يمثل الأول مجموعة العلاقات الافتراضية للأشخاص، ويمثل الثاني مجموعة صفحات الأشخاص وارتباط المعلومات فيها. ويرتبط الحيزان معًا بروابط بين العقد الممثلة للأشخاص في الحيز الأول والعقد الممثلة للصفحات في الحيز الثاني كما هو مبين في الشكل 8.
الشكل 8: شكل متقدم لتمثيل شبكات التواصل الاجتماعي
تتطلب المعلومات الممثلة في الطريقتين السابقتين تحديثًا دائمًا نظرًا للتغيرات المستمرة في هذه المعلومات. بعد عملية التمثيل، تأتي المرحلة الأهم وهي عملية البحث ضمن شبكة التواصل الاجتماعي، حيث تتبع النظم استراتيجيات خاصة لإجراء عملية البحث هذه. أهم هذه الاستراتيجيات تسخير مفاهيم البحث الدلالي لاستخراج المعلومات والعلاقات الموجودة في شبكات التواصل الاجتماعي.
يعتبر مفهوم الأنطولوجيا (Ontology) من المفاهيم المهمة في مجال التمثيل الدلالي للمعلومات. حيث تحتوي على الكثير من التمثيلات الممكنة لمجموعة العلاقات والروابط. تعتبر أنطولوجية FOAF (Friend Of A Friend) من أهم الأنطولوجيات المستعملة في مجال التمثيل الدلالي ضمن نظم استرجاع المعلومات الخاصة بشبكات التواصل. إذ إنها تحتوي على جميع التمثيلات الممكنة لمجموعة العلاقات والروابط بين الأفراد وبناءً على ذلك يمكن استخراج العلاقات الموجودة في شبكات التواصل الاجتماعي. وتعتمد هذه الأنطولوجية المعايير المتبعة في مجال الوب الدلالي لتمثيل محتواها وذلك باعتماد لغة التمثيل الدلالية RDF (Resource Description Framework ) ولغة OWL (Ontology Web Language )، وهذا مما يمكّن نظم استرجاع المعلومات من استعمالها استعمالًا قياسيًّا. إحدى الأنطولوجيات المهمة أيضًا هي SIOC (Semantically-Interlinked Online Communities) وهي تعتمد أيضًا على تمثيل RDF/OWL، كما تتميز بمستوى أعلى من التجريد عن FOAF.
ولتحسين طريقة تمثيل العلاقات ضمن شبكات التواصل الاجتماعي وسهولة البحث فيها، جرى اعتماد تمثيلات معيارية أكثر تضمن سهولة مكاملة الأنطولوجيات الخاصة بشبكات التواصل الاجتماعي، ومن هذه الطرق شبكة XFN (XHTML Friends Network) (يرمز المصطلح XHTML إلى Extensible Hypertext Markup Language). حيث توفر الشبكة XFN بنية مثالية لتمثيل العلاقات اعتمادًا على لغة التنميط المعيارية XHTML.
تقييم أداء نظم استرجاع المعلومات ضمن شبكات التواصل الاجتماعي
يعتمد تقييم هذه النظم على عدة معايير؛ مثل: حجم شبكة التواصل الاجتماعي التي يجري البحث فيها، وسرعة البحث، ودقة الإجابة، وعدد الأجوبة، وترتيب الأجوبة، وطريقة إظهار الجواب، والقدرة على اقتراح بدائل أخرى للاستعلام في حال عدم العثور على الجواب المطلوب، إضافة إلى معايير أخرى.
تعتمد بعض النظم المعايير المتبعة في المؤتمرات العالمية مثل CLEF (Conference and Labs of the EvaluationForum)، و TREC (Text Retrieval Conference)، و EQueR-EVALDA، و INEX، و Quaero، وغيرها من المؤتمرات أو الأحداث العالمية. ويقيَّم أداء النظم أيضًا بالاعتماد على معيارين مهمين جدًّا في مجال استرجاع المعلومات؛ هما: الدقة Precision، والاستدعاء Recall (أو التغطية).
أما الدقة فتعرَّف بأنها نسبة عدد الصفحات المستردة من نظام استرجاع المعلومات التي لها علاقة بالسؤال المطروح على عدد كل الصفحات المستردة من النظام. وأما الاستدعاء فيعرَّف بأنه نسبة عدد الصفحات المستردة من نظام استرجاع المعلومات التي لها علاقة بالسؤال المطروح على عدد كل الصفحات الموجودة في فهرس النظام. يعتمد هذان المعياران على مفهوم ارتباط الصفحة المستردة بالسؤال المطروح أو عدم ارتباطها، وبمفهوم استرجاع الصفحة ذات الارتباط أو عدم استرجاعها. إذ تعرَّف الصفحة التي ترتبط بالسؤال بأنها الصفحة التي تحتوي مفردات تتقاطع مع مفردات السؤال المطروح.
الخاتمة
إنّ نظم استرجاع المعلومات الخاصة بشبكات التواصل الاجتماعي تشكّل نقلة نوعية في مفاهيم استرجاع المعلومات والتنقيب فيها، وتهيئ طريقة فعالة ومتقدمة للبحث عن المعلومات. وتقدم الإصدارات الحديثة من هذه النظم أساليب متقدمة للتفاعل مع تقنيات الوب الدلالي باعتماد مفاهيم الأنطولوجيات والشبكات الدلالية.
المراجع
Book "Introduction to Information Retrieval", Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Cambridge University Press. 2008
"Social networks and information retrieval, how are theyconverging? A survey, a taxonomy and an analysis of socialinformation retrieval approaches and platforms", Mohamed Reda Bouadjeneka,b,n, Hakim Hacidc, Mokrane Bouzeghoub, Journal of Information Systems Volume 56, March 2016, Pages 1-18.
"Social Information Retrieval and Recommendation:state- of-the-art and future research", Abir Gorrab, Ferihane Kboubi and Henda Ben Ghezala, ARIMA Journal, vol. 27, pp. 121-136 (2019).
 تكنولوجيا الهاتف المحمول والعمل المصرفي
تكنولوجيا الهاتف المحمول والعمل المصرفي الهادوب وإدارة وتحليل البيانات الضخمة
الهادوب وإدارة وتحليل البيانات الضخمة